We analyze visuomotor policy learning as action decoding from video generation, paving the way for more scalable and data-efficient robot learning.
Abstract
Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
Action-free Video Training
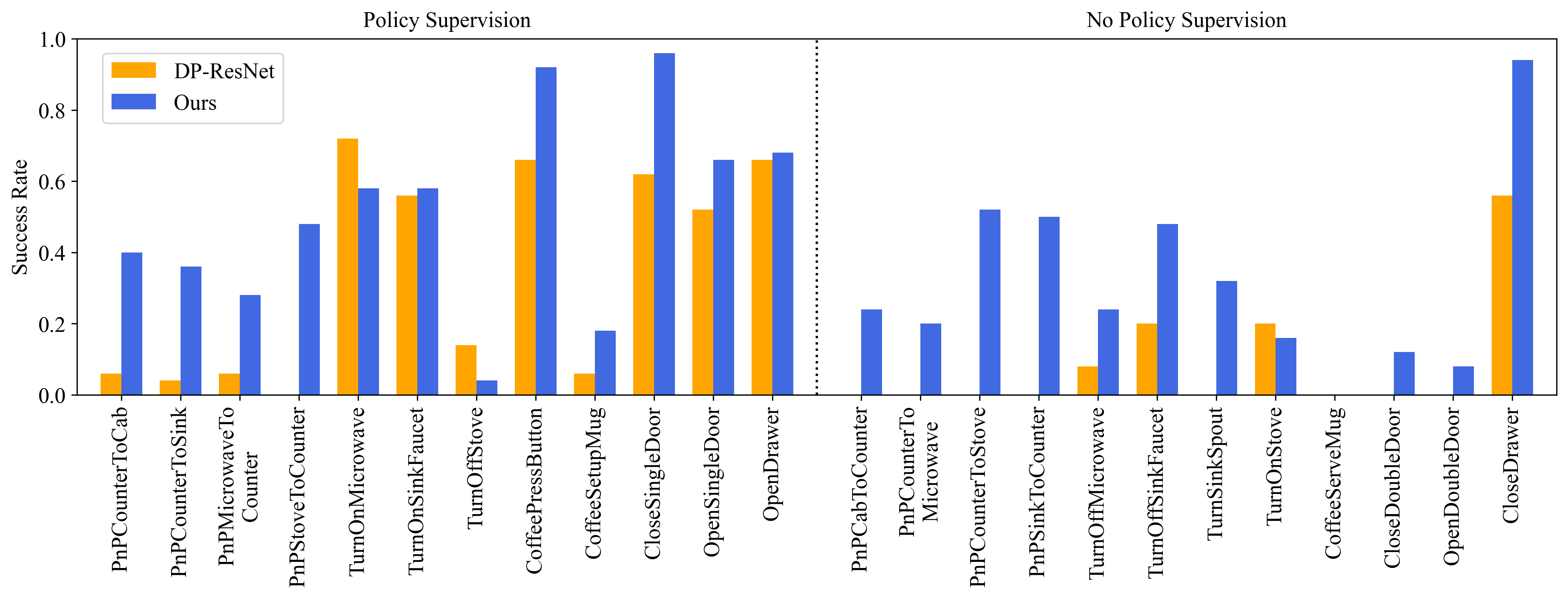
Example Tasks with Action-free Video Training Only
PnPCabToCounter
PnPCounterToMicrowave
PnPCounterToStove
PnPSinkToCounter
TurnOffMicrowave
TurnOffSinkFaucet
TurnSinkSpout
TurnOnStove
CoffeeServeMug
CloseDoubleDoor
OpenDoubleDoor
CloseDrawer
Walk-through Video
Video Generation as a Policy Learning Objective
2-stage training first optimizes for video generation, then freezes the video U-Net and trains an action head, while joint training finetunes both objectives simultaneously. Notably, 2-stage training achieves significantly higher success rates, indicating that video generation serves as a more general learning objective than action prediction.

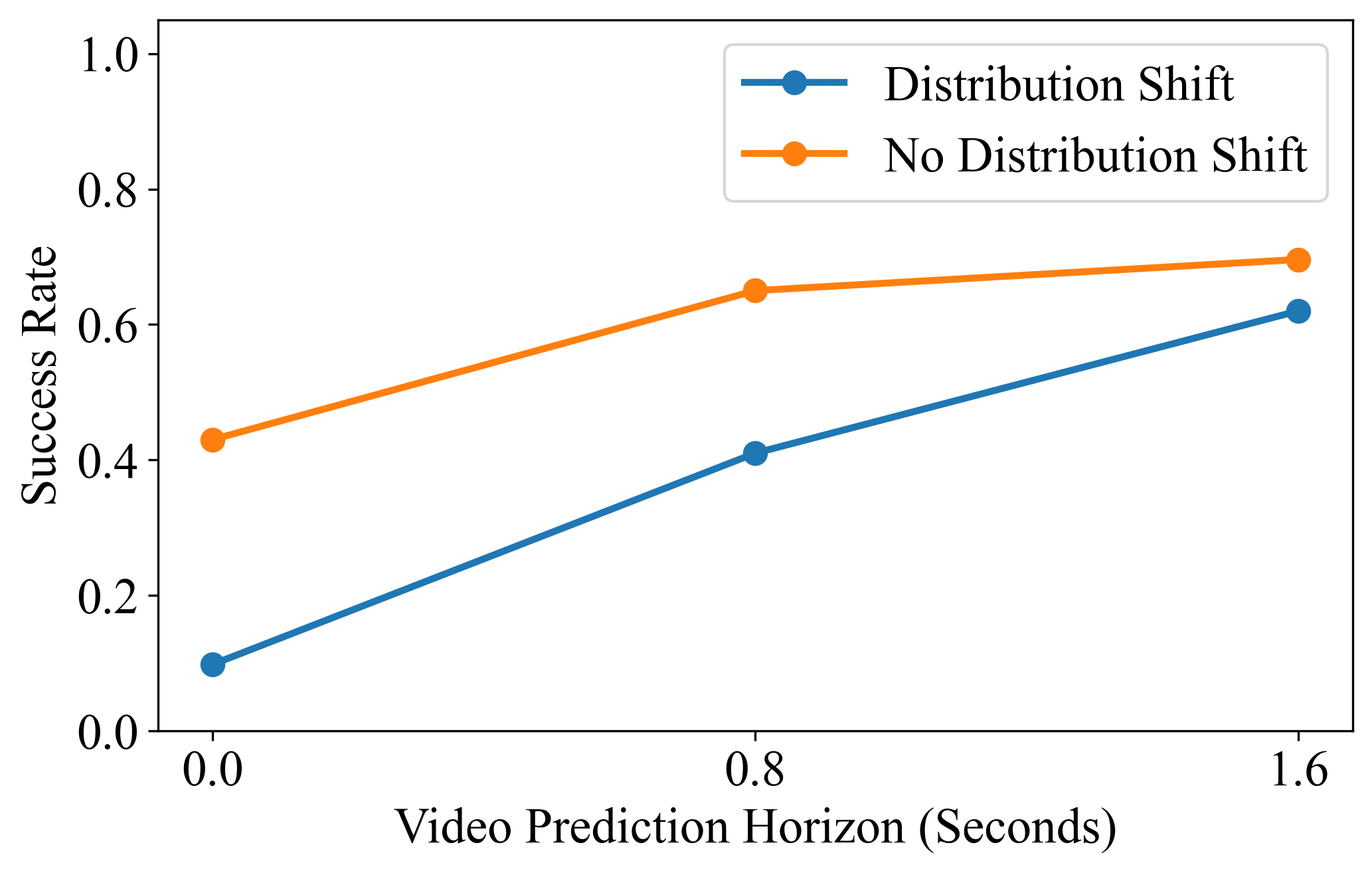
Success Rate vs Video Prediction Horizon
We plot average task success rates, separating tasks with and without distribution shifts between training and evaluation environments, as a function of the model's video prediction horizon. While longer-term video prediction consistently improves performance, its impact is more pronounced on tasks that demand stronger generalization. These results highlight that learning accurate environment dynamics is critical for achieving generalization in policy learning.
Real-World Evaluation
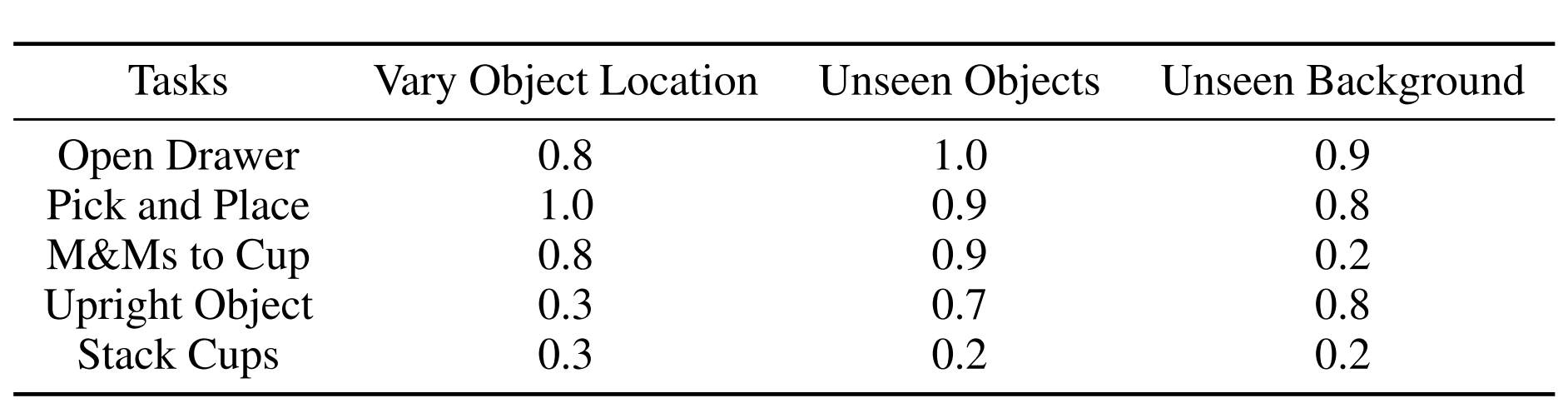
Real-World Experiments with Varied Object Location
Open Drawer
Pick and Place
M&Ms to Cup
Upright Object
Stack Cups
Real-World Experiments with Unseen Objects
Open Drawer
Pick and Place
M&Ms to Cup
Upright Object
Stack Cups
Real-World Experiments with Unseen Background
Open Drawer
Pick and Place
M&Ms to Cup
Upright Object
Stack Cups
BibTeX
@article{liang2025video,
title={Video Generators are Robot Policies},
author={Liang, Junbang and Tokmakov, Pavel and Liu, Ruoshi and Sudhakar, Sruthi and Shah, Paarth and Ambrus, Rares and Vondrick, Carl},
journal={arXiv preprint arXiv:2508.00795},
year={2025}
}